

Speech To Text ( STT ) recognition. This is also known as Automated Speech Recognition (ASR).
Voice or speaker recognition is the ability of a machine or program to receive and interpret to understand and carry out spoken commands. Voice recognition systems enable consumers to interact with technology simply by speaking to it, enabling hands-free requests, reminders and other simple tasks. Technologies that enable the recognition and translation of spoken language into text by computers.
I hope all can be agreed on point that even before we got introduced with characters or words the medium of communication was voice. Even after social media introduced and we started falling in love to the do chatting with peoples, But now we are more preferring images and videos calls.

Why speech to text ?
STT enabled software are convenient because software can understand the voice and produces text based on learning. STT software is fast because it doesn’t need time for typing. STT software can boost productivity results profitability.
How it works ?
Web Speech API is the key of supporting voice recognition for example webkitSpeechRecognition, The Web Speech API provides two distinct areas of functionality — speech recognition, and speech synthesis (also known as text to speech, or tts) — which open up interesting new possibilities for accessibility, and control mechanisms. This article provides a simple introduction to both areas, along with demos. Know more
How to use in Angular applications ?
For implementing web speech recognition, We need to create a service called voice-recognition.service.ts that can be used in any components in the application. We are using webkitSpeechRecognition (Only supports in Chrome ) which is api with prefix wbkit. We can also use SpeechRecognition ( for the Firefox ) or we can use both apis based on the browsers.
In above service there are main three functions (init, start, stop)responsible for handling voice input and producing output.
Initialisation : Init is responsible for initialising the SpeetchRecognition API. At this point the application has not yet started listening to voice input, just the instance of API has been created.
Note : This will return an observable and the handler of this observable will be only executed when the user disables mic.
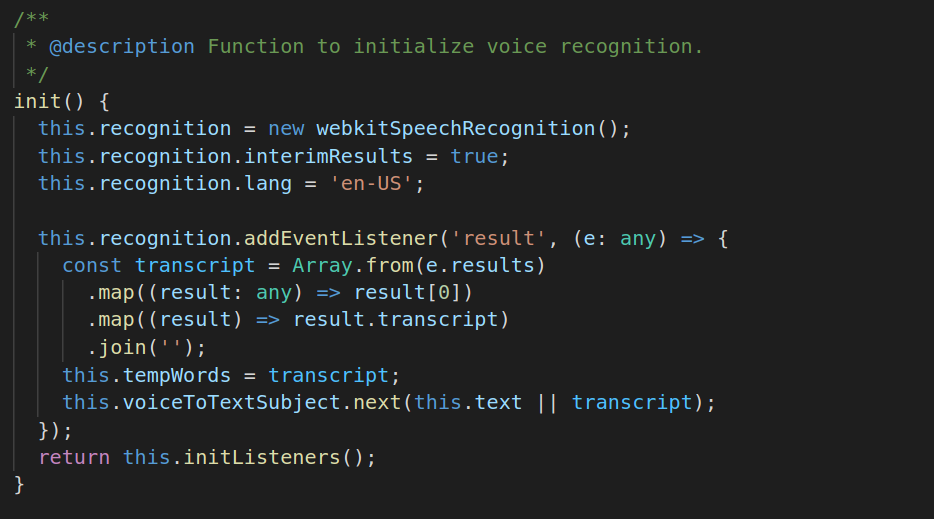
We have initialised the API and have set interimResults to true which configures that, we will be getting speech output even when the user is speaking otherwise the result will only be available when the user stops speaking or mic gets off.
Language can be set using lang property. Currently it is ‘en-US’ which is US English for me. Supported languages
Then I have added a listener result to the recognition instance to get the result of voice samples as text output to transcript local variable.
There is a custom rxjs Subject named voiceToTextSubject which delivers the sample result to components, for that init function must be subscribed.
Start listening : Start function will enable the voice input. We can call this function on button click or any other action when to turn on mic.
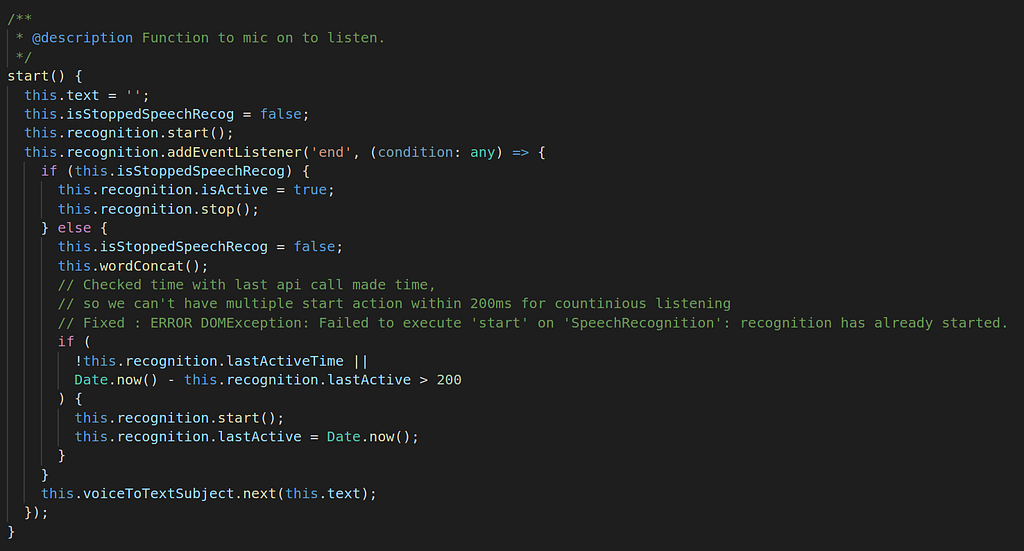
In recognition instance we have added a end event handler this will callback when the active instance will stop listening.
Note : In the above function the main problem is that browser will stop listening after 30 sec to 45 sec.
Solution: To fix this problem we will need to start recognition again when it stops listening and need to keep backup of the last output. For that we have used end event and this.text variables in the service. Now the listening will not stop for ever so it requires to create a function to stop listening.
Stop Listening : This function can be used for stop listening.
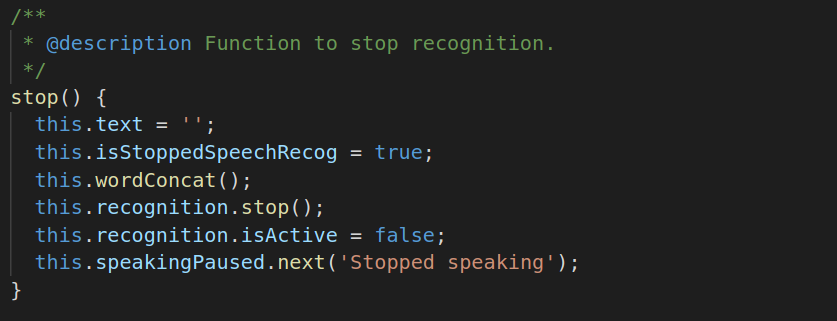
Getting Voice Output: We will need to subscribe voice to text subject using speechInput function. This function returns observable and will return text output on every voice synthesis.

VoiceRecognitionService Complete Code
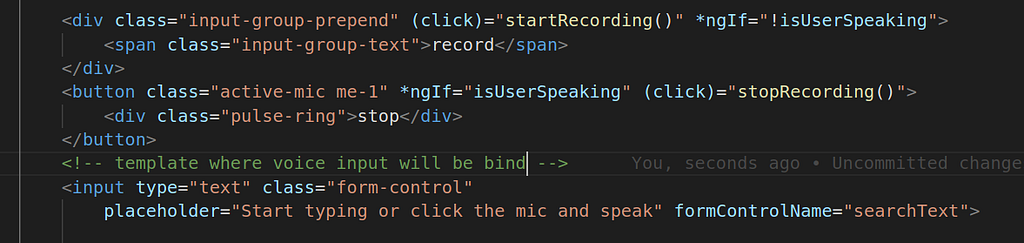
Component Template : In the template file there are two buttons to enable and disable the mic. There is one input field that will be used to render the STT outputs.
Please give me feedback for the difficulty level of understanding this documentation.
You can also read voice synthesis Part 2 here
Happy reading…..